主要内容:
- 编写第一个 Node.js 程序
- 异步式 I/O 和事件循环
- 模块和包
- 调试
Node.js 快速入门
Node.js 具有深厚的开源血统,它诞生于托管了许多优秀开源项目的网站—— github。
开始使用 Node.js 编程
Hello World
打开常用文本编辑器,输入
1 | console.log('Hello World'); |
文件保存为 helloworld.js ,打开终端,进入文件所在的目录,执行以下命令
1 | node helloworld.js |
就可以在终端看到输出 Hello World
console 是 Node.js 提供的控制台对象,其中包含了向标准输出写入的操作,如 console.log 、console.error
Node.js 命令行工具
终端输入 node –help 可以看到详细的帮助信息。
C:\Users\Administrator\Desktop>node –help
Usage: node [options][ -e script | script.js | - ] [arguments]
node inspect script.js [arguments]Options:
-v, –version print Node.js version
-e, –eval script evaluate script
-p, –print evaluate script and print result
-c, –check syntax check script without executing
-i, –interactive always enter the REPL even if stdin
does not appear to be a terminal
-r, –require module to preload (option can be repeated)
- script read from stdin (default; interactive mode i
f a tty)
–inspect[=[host:]port] activate inspector on host:port
(default: 127.0.0.1:9229)
–inspect-brk[=[host:]port]
activate inspector on host:port
and break at start of user script
–inspect-port=[host:]port
set host:port for inspector
–no-deprecation silence deprecation warnings
–trace-deprecation show stack traces on deprecations
–throw-deprecation throw an exception on deprecations
–pending-deprecation emit pending deprecation warnings
–no-warnings silence all process warnings
–napi-modules load N-API modules (no-op - option
kept for compatibility)
–abort-on-uncaught-exception
aborting instead of exiting causes a
core file to be generated for analysis
–trace-warnings show stack traces on process warnings
–redirect-warnings=file
write warnings to file instead of
stderr
–trace-sync-io show stack trace when use of sync IO
is detected after the first tick
–force-async-hooks-checks
enables checks for async_hooks
–trace-events-enabled track trace events
–trace-event-categories comma separated list of trace event
categories to record
–track-heap-objects track heap object allocations for heap snapshots
–prof-process process v8 profiler output generated
using –prof
–zero-fill-buffers automatically zero-fill all newly allocated
Buffer and SlowBuffer instances
–v8-options print v8 command line options
–v8-pool-size=num set v8’s thread pool size
–tls-cipher-list=val use an alternative default TLS cipher list
–use-bundled-ca use bundled CA store (default)
–use-openssl-ca use OpenSSL’s default CA store
–openssl-config=file load OpenSSL configuration from the
specified file (overrides
OPENSSL_CONF)
–icu-data-dir=dir set ICU data load path to dir
(overrides NODE_ICU_DATA)
–preserve-symlinks preserve symbolic links when resolving
–experimental-modules experimental ES Module support
and caching modulesEnvironment variables:
NODE_DEBUG ‘,’-separated list of core modules
that should print debug information
NODE_DISABLE_COLORS set to 1 to disable colors in the REPL
NODE_EXTRA_CA_CERTS path to additional CA certificates
file
NODE_ICU_DATA data path for ICU (Intl object) data
NODE_NO_WARNINGS set to 1 to silence process warnings
NODE_NO_HTTP2 set to 1 to suppress the http2 module
NODE_OPTIONS set CLI options in the environment
via a space-separated list
NODE_PATH ‘;’-separated list of directories
prefixed to the module search path
NODE_PENDING_DEPRECATION set to 1 to emit pending deprecation
warnings
NODE_REPL_HISTORY path to the persistent REPL history
file
NODE_REDIRECT_WARNINGS write warnings to path instead of
stderr
OPENSSL_CONF load OpenSSL configuration from fileDocumentation can be found at https://nodejs.org/
其中显示了 node 的用法,运行 Node.js 程序的基本方法就是执行 node script.js ,其中 script.js 是脚本的文件名。
除了直接运行脚本文件外, node –help 显示的使用方法中说明了另一种输出 Hello
World 的方式:
1 | node -e "console.log('Hello World');" |
我们可以把要执行的语句作为 node -e 的参数直接执行。
使用 node 的 REPL 模式
REPL (Read-eval-print loop),即输入—求值—输出循环,运行无参数的 node 将会启动一个 JavaScript的交互式 shell:
1 | node |
进入 REPL 模式以后,会出现一个“ > ”提示符提示你输入命令,输入后按回车,Node.js
将会解析并执行命令。如果你执行了一个函数,那么 REPL 还会在下面显示这个函数的返回值.
如果你输入了一个错误的指令,REPL 则会立即显示错误并输出调用栈。在任何时候,连续按两次 Ctrl + C 即可推出Node.js 的 REPL 模式。
建立 HTTP 服务器
Node.js 是为网络而诞生的平台,但又与 ASP、PHP 有很大的不同,究竟不同在哪里呢?
PHP 架构是一种“浏览器 - HTTP 服务器 - PHP 解释器”的组织方式。而 Node.js 则是 “浏览器 - Node”
创建一个HTTP 服务器,建立一个名为 app.js 的文件,内容如下:
1 | var http = require('http'); |
接下来运行 node app.js 命令,打开浏览器访问 http://127.0.0.1:3000 就可以看到以下内容
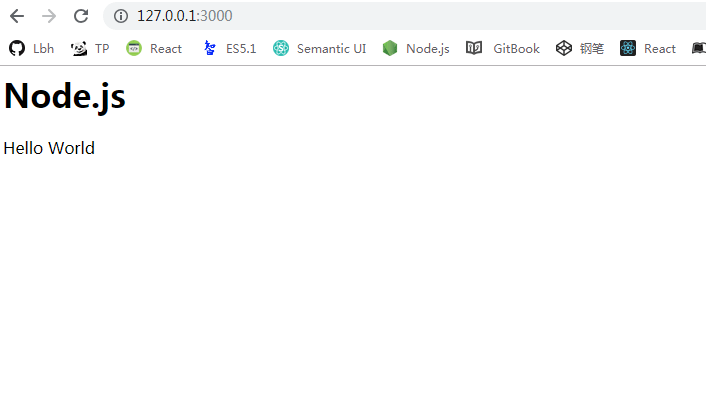
用 Node.js 实现的最简单的 HTTP 服务器就这样诞生了。这个程序调用了 Node.js 提供的http 模块,对所有 HTTP 请求答复同样的内容并监听 3000 端口。在终端中运行这个脚本时,我们会发现它并不像 Hello World 一样结束后立即退出,而是一直等待,直到按下 Ctrl +C 才会结束。这是因为 listen 函数中创建了事件监听器,使得 Node.js 进程不会退出事件循环。
小技巧——使用 supervisor
upervisor 监视你对代码的改动,并自动重启 Node.js,但是浏览器还是得手动刷新。使用方法很简单,首先使用 npm 安装 supervisor:
1 | supervisor app.js |
当代码变化的时候,运行的脚本会被终止,然后重新启动:
1 | crashing child |
supervisor 这个小工具可以解决开发中的调试问题。
异步式 I/O 与事件式编程
Node.js 最大的特点就是异步式 I/O(或者非阻塞 I/O)与事件紧密结合的编程模式。这种模式与传统的同步式 I/O 线性的编程思路有很大的不同,因为控制流很大程度上要靠事件和回调函数来组织,一个逻辑要拆分为若干个单元。
阻塞与线程
什么是阻塞(block)呢?线程在执行中如果遇到磁盘读写或网络通信(统称为 I/O 操作),通常要耗费较长的时间,这时操作系统会剥夺这个线程的 CPU 控制权,使其暂停执行,同时将资源让给其他的工作线程,这种线程调度方式称为 阻塞。当 I/O 操作完毕时,操作系统将这个线程的阻塞状态解除,恢复其对CPU的控制权,令其继续执行。这种 I/O 模式就是通常的同步式 I/O(Synchronous I/O)或阻塞式 I/O (Blocking I/O)。
相应地,异步式 I/O (Asynchronous I/O)或非阻塞式 I/O (Non-blocking I/O)则针对所有 I/O 操作不采用阻塞的策略。当线程遇到 I/O 操作时,不会以阻塞的方式等待 I/O 操作的完成或数据的返回,而只是将 I/O 请求发送给操作系统,继续执行下一条语句。当操作系统完成 I/O 操作时,以事件的形式通知执行 I/O 操作的线程,线程会在特定时候处理这个事件。为了处理异步 I/O,线程必须有事件循环,不断地检查有没有未处理的事件,依次予以处理。
阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行计算操作,这个线程所使用的 CPU 核心利用率永远是 100%,I/O 以事件的方式通知。在阻塞模式下,多线程往往能提高系统吞吐量,因为一个线程阻塞时还有其他线程在工作,多线程可以让 CPU 资源不被阻塞中的线程浪费。而在非阻塞模式下,线程不会被 I/O 阻塞,永远在利用 CPU。多线程带来的好处仅仅是在多核 CPU 的情况下利用更多的核,而Node.js的单线程也能带来同样的好处。这就是为什么 Node.js 使用了单线程、非阻塞的事件编程模式。
假设我们有一项工作,可以分为两个计算部分和一个 I/O 部分,I/O 部分占的时间比计算多得多(通常都是这样)。如果我们使用阻塞 I/O,那么要想获得高并发就必须开启多个线程。而使用异步式 I/O时,单线程即可胜任。
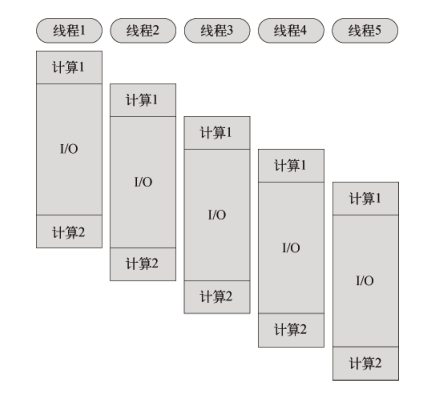
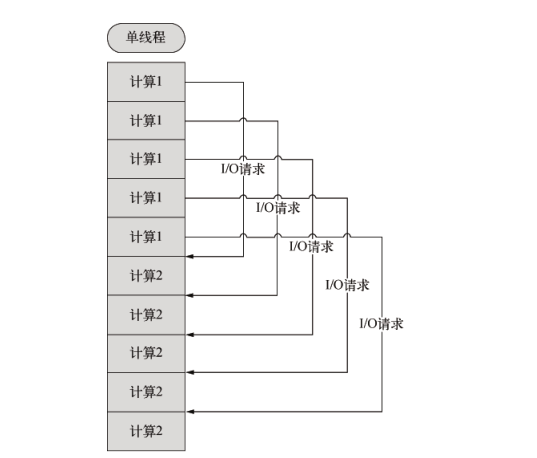
单线程时间驱动的异步式 I/O 比传统的多线程阻塞式 I/O 究竟好在哪里?
简而言之。异步式 I/O 就是少了多线程的开销,对操作系统来说,创建一个线程的代价是十分昂贵的,需要给它分配内存,列入调度,同时在线程切换的时候还要执行内存换页,CPU 的缓存被清空,切换回来的时候还要重新从内存中读取信息,破坏了数据的局限性(基于多线程的模型也有相应的解决方案,如轻量级线程(lightweight thread)等。事件驱动的单线程异步模型与多线程同步模型到底谁更好是一件非常有争议的事情,因为尽管消耗资源,后者的吞吐率并不比前者低。)。
当然异步式编程的缺点在于不符合人们一把你的程序设计思维,容易让控制流变得晦涩难懂,给编码和调试都带来了不小困难。
下表比较了同步式 I/O 和异步式 I/O 的特点。
| 同步I/O(阻塞式) | 异步式I/O(非阻塞式) |
|---|---|
| 利用多线程提供吞吐量 | 单线程即可实现高吞吐量 |
| 通过事件片分割和线程调度利用多核 CPU | 通过功能划分利用多核 CPU |
| 需要操作由操作系统调度多线程使用多核 CPU | 可以将单进程绑定到单核 CPU |
| 难以充分利用 CPU 资源 | 可以充分利用 CPU 资源 |
| 内存轨迹大、数据局部性弱 | 内存轨迹小、数据局部性强 |
| 符合线性的编程思维 | 不符合传统编程思维 |
回调函数
Node.js 中如何使用异步的方式读取一个文件,例子如下:
file.text
1 | 你好呀! |
1 | // readfile.js |
运行结果如下
1 | end |
Node.js 也提供了同步读取文件的 API
1 | //readfilesync.js |
运行的结果与上一个有点不一样
1 | node readfilesync.js |
同步式读取文件时,将文件名作为参数传入 fs.readFileSync 函数,阻塞等待读取完成后,将文件的内容作为函数的返回值赋给 data 变量,接下来,控制台输出 data 的值,最后输出 end。
异步式读取文件则是 end 先被输出。fs.readFile 接受了三个参数,第一个是文件名,第二个是编码方式,第三个是一个函数,我们称这个函数为回调函数。 JavaScript 支持匿名的函数定义方式。这种定义方式在 JavaScript 程序中极为普遍,与下面这种定义方式实现的功能是一致的:
1 | //readfilecallback.js |
fs.readFile 调用时所做的工作只是将异步式 I/O 请求发送给了操作系统,然后立即返回并执行了后面的语句,执行完以后进入事件循环监听事件。当 fs 接受到了 I/O 请求完成的事件时,事件循环会主动调用函数以后完成后续工作。因此我们会先看到 end ,然后再看到 文件中的内容。
事件
Node.js 所有异步 I/O 操作在完成时都会发送一个事件到事件队列。事件由 EventEmitter 对象提供。fs.readFile 和 http.createServer 的回调函数都是通过 EventEmitter 来实现的。
1 | // event.js |
运行这段代码,1秒后控制台输出了 some_event occured. 。其原理是 event 对象注册了事件 some_event 的一个监听器,然后我们通过 setTimeout 在1000毫秒以后向event 对象发送事件 some_event ,此时会调用 some_event 的监听器。
Node.js 的事件循环机制
Node.js 在什么时候会进入事件循环呢?
Node.js 程序由事件循环开始,直到事件循环结束,所有逻辑都是事件的回调函数,所以 Node.js 始终在事件循环中,程序入口就是事件循环第一个事件的回调函数。事件的回调函数在执行的过程中,可能会发出 I/O 请求或直接发射(emit)事件,执行完毕后再返回事件循环,事件循环会检查事件队列中有没有未处理的事件,直到程序结束。下图说明了事件循环的原理。
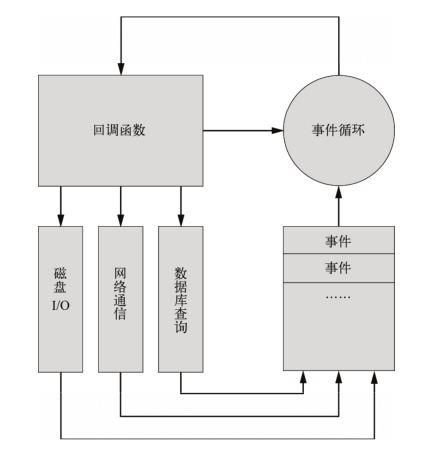
与其他语言不同的是,Node.js 没有显式的事件循环。Node.js 的事件循环对开发者不可见,由 libev 库实现。 libev支持多种类型的事件,如 ev_io 、 ev_timer 、 ev_signal 、 ev_idle 等,在 Node.js 中均被EventEmitter 封装。 libev 事件循环的每一次迭代,在 Node.js 中就是一次 Tick, libev 不断检查是否有活动的、可供检测的事件监听器,直到检测不到时才退出事件循环,进程结束。
模块和包
模块(Module)和包(Package)是 Node.js 最重要的支柱。开发一个具有一定规模的程序不可能只用一个文件,通常需要把各个功能拆分、封装,然后组合起来,模块正是为了实现这种方式而诞生的。在浏览器 JavaScript 中,脚本模块的拆分和组合通常使用 HTML 的script 标签来实现。Node.js 提供了 require 函数来调用其他模块,而且模块都是基于文件的,机制十分简单。
Node.js 的模块和包机制的实现参照了 CommonJS 的标准,但并未完全遵循。不过两者的区别并不大。只有试图制作一个除了支持 Node.js之外还要支持其他平台的模块或包的时候才需要仔细研究。通常,两者没有直接冲突的地方。
我们经常把 Node.js 的模块和包相提并论,因为模块和包是没有本质区别的,两个概念也时常混用。如果要辨析,那么可以把包理解成是实现了某个功能模块的集合,用于发布和维护。对使用者来说,模块和包的区别是透明的,因此经常不作区分。
什么是模块
模块是 Node.js 应用程序的基本组成部分,文件和模块是一一对应的。换言之,一个Node.js 文件就是一个模块,这个文件可能是 JavaScript 代码、JSON 或者编译过的 C/C++ 扩展。
在前面例子中,曾经用到了 var http = require(‘http’), 其中 http是 Node.js 的一个核心模块,其内部是用 C++ 实现的,外部用 JavaScript 封装。我们通过require 函数获取了这个模块,然后才能使用其中的对象。
创建及加载模块
创建模块
Node.js 中,一个文件就是一个模块,Node.js提供了 exports 和 require 两个对象,其中 exports 是模块公开的接口, require 用于从外部获取一个模块的即可欧,即获取模块的 exports 对象。
创建一个 module.js 文件。
1 | // module.js |
在同一目录下,创建一个 getmodule.js
1 | // getmodule.js |
运行node getmodule.js,结果是:
1 | Hello NodeJs |
在以上示例中,module.js 通过 exports 对象把 setName 和 sayHello 作为模块的访问接口,在 getmodule.js 中通过 require('./module') 加载这个模块,然后就可以直接访问 module.js 中 exports 对象的成员函数了。
这种接口封装方式比许多语言要简洁得多,同时也不失优雅,未引入违反语义的特性,符合传统的编程逻辑。在这个基础上,我们可以构建大型的应用程序,npm 提供的上万个模块都是通过这种简单的方式搭建起来的。
单次加载
上面这个例子有点类似于创建一个对象,但实际上和对象又有本质的区别,因为 require 不会重复加载模块,也就是说无论调用多少次 require, 获得的模块都是同一个。在 getmodule.js 的基础上稍作修改:
1 | //loadmodule.js |
运行后发现输出结果是 NAME 2 ,这是因为变量 hello1 和 hello2 指向的是同一个实例,因此 hello1.setName 的结果被 hello2.setName 覆盖,最终输出结果是由后者决定的。
覆盖 exports
有时候我们只是想把一个对象封装到模块中,例如:
1 | //singleobject.js |
此时我们在其他文件中需要通过 require(‘./singleobject’).Hello 来获取Hello 对象,这略显冗余,可以用下面方法稍微简化:
1 | //hello.js |
这样就可以直接获得这个对象了
1 | //gethello.js |
注意,模块接口的唯一变化是使用 module.exports = Hello 代替了 exports.Hello=Hello 。在外部引用该模块时,其接口对象就是要输出的 Hello 对象本身,而不是原先的exports 。
事实上, exports 本身仅仅是一个普通的空对象,即 {} ,它专门用来声明接口,本
质上是通过它为模块闭包的内部建立了一个有限的访问接口。因为它没有任何特殊的地方,所以可以用其他东西来代替,如上面例子中的 Hello 对象。
不可以通过对 exports 直接赋值代替对 module.exports 赋值。exports 实际上只是一个和 module.exports 指向同一个对象的变量,它本身会在模块执行结束后释放,但 module 不会,因此只能通过指定module.exports 来改变访问接口。
创建包
包是在模块基础上更深一步的抽象,Node.js 的包类似于 C/C++ 的函数库或者 Java/.Net 的类库。它将某个独立的功能封装起来,用于发布、更新、依赖管理和版本控制。Node.js 根据 CommonJS 规范实现了包机制,开发了 npm 来解决包的发布和获取需求。
Node.js 的包是一个目录,其中包含了一个 JSON 格式的包说明文件 package.json 。严格符合 CommonJS 规范的包应该具备以下特征。
- package.json 必须在包的目录下;
- 二进制文件应该在 bin 目录下;
- JavaScript 代码应该在 lib 目录下
- 文档应该在 doc 目录下
- 单元测试应该在 test 目录下
Node.js 对包的要求并没有这么严格。只要顶层目录下有一个 package.json,并符合一些规范即可。当然为了提高兼容性,还是建议在制作包的时候,严格遵守 CommonJS 规范。
作为文件夹的模块
模块与文件是一一对应的。文件不仅可以是 JavaScript 代码或二进制代码,还可以是一个文件夹。最简单的包,就是一个作为文件夹的模块。下面我们来看一个例子,建立一个叫做 somepackage 的文件夹,在其中创建 index.js,内容如下:
1 | //somepackage/index.js |
然后在 somepackage 之外建立 getpackage.js 内容如下:
1 | // getpackage.js |
运行 node getpackage.js,控制台将输出结果 Hello. 。
使用这种方法可以把文件夹封装为一个模块,即所谓的包。包通常是一些模块的集合,在模块的基础上提供了更高层的抽象,相当于提供了一些固定接口的函数库。通过定制package.json,我们可以创建更复杂、更完善、更符合规范的包用于发布。
package.json
在somepackage 文件夹下,创建一个叫做 package.json 的文件,内容如下:
1 | { |
然后将 index.js 重命名为 interface.js 并放入 lib 文件夹下面。以同样的方式再次调用这个
包,依然可以正常使用。
Node.js 在调用某个包时,会首先检查包中 package.json 文件的 main 字段,将其作为包的接口模块,如果 package.json 或 main 字段不存在,会尝试寻找 index.js 或 index.node 作为包的接口。
package.json 是 CommonJS 规定的用来描述包的文件,完全符合规范的 package.json 文件应该含有以下字段。
- name:包的名称,必须是唯一的,由小写英文、数字和下划线组成,不能包含空格。
- description:包的简要说明。
- version:符合语义化版本识别规范的版本字符串。
- keywords:关键字数组,通常用于搜索、
- maintainers:维护者数组,每个元素要包含 name、email(可选)、web(可选)字段。
- contributions:贡献者数组,格式和 maintainers 相同。包的作者应该是贡献者数组的第一个元素。
- bugs:提交 bug 的地址,可以是网址或者是电子邮件地址。
- license:许可证数组,每个元素要包含 type(许可证的名称)和 url (链接到许可证文本的地址)子段。
- respositories:仓库托管地址数组,每个元素要包含 type (仓库的类型,如 git)、url(仓库的地址)和 path(相对于仓库的路径,可选)字段。
- dependencies:包的依赖,一个关联数组,由包名称和版本号组成。
下面是一个完全符合 CommonJS 规范的 package.json 示例:
1 | { |
Node.js 包管理器
Node.js包管理器,即 npm 是 Node.js 官方提供的包管理工具,它已经成了 Node.js 包的标准发布平台,用于 Node.js 包的发布、传播、依赖控制。npm 提供了命令行工具,使你可以方便地下载、安装、升级、删除包,也可以让你作为开发者发布并维护包。
获取一个包
使用 npm 安装包的命令格式为:
npm [install/i][package_name]
例如你要安装 express ,可以在命令行运行:
$ npm install express
或者:
$ npm i express
express 安装成功之后被放置在当前目录的 node_modules 子目录下。npm 在获取 express 的时候还将自动解析其依赖,并获取 express 依赖的 mime 、 mkdirp 、qs 和 connect 。
本地模式和全局模式
npm 在默认情况下会从http://npmjs.org搜索或下载包,将包安装到当前目录的 node_modules 子目录下。
在使用 npm 安装包的时候,有两种模式:本地模式和全局模式。默认情况下我们使用 npm install 命令就是采用本地模式,即把包安装到当前目录的 node_modules 子目录下。Node.js 的 require 在加载模块时会尝试搜寻 node_modules 子目录,因此使用 npm 本地模式安装的包可以直接被引用。
npm 还有另一种不同的安装模式被成为全局模式,使用方法为:
npm [install/i] -g [package_name]
与本地模式的不同之处就在于多了一个参数 -g 。
为什么要使用全局模式呢?多数时候并不是因为许多程序都有可能用到它,为了减少多重副本而使用全局模式,而是因为本地模式不会注册 PATH 环境变量。
我们安装 supervisor 是为了在命令行中运行它,假如直接运行 supervisor script.js,这时就需要在 PATH 环境变量中注册 supervisor。npm 本地模式仅仅是把包安装到 node_modules 子目录下,其中的 bin 目录没有包含在 PATH 环境变量中,不能直接在命令行中调用。而当使用全局模式安装时,npm 会将包安装到系统目录,譬如/usr/local/lib/node_modules/,同时 package.json 文件中 bin 字段包含的文件会被链接到 /usr/local/bin/。/usr/local/bin/ 是在 PATH 环境变量中默认定义的,因此就可以直接在命令行中运行 supervisor script.js 命令了。
使用全局模式安装的包并不能直接在 JavaScript 文件中用 require 获得,因为 require 不会搜索 /usr/local/lib/node_modules/。
本地模式和全局模式的特点
| 模式 | 可通过 require 使用 | 注册 PATH |
|---|---|---|
| 本地模式 | 是 | 否 |
| 全局模式 | 否 | 是 |
总而言之,要把某个包作为工程运行时的一部分时,通过本地模式获取,如果要在命令行下使用,则使用全局模式安装。
创建全局链接
npm 提供了一个有趣的命令 npm link, 它的功能是在本地包和全局包之间创建符号链
接。使用全局模式安装的包不能直接通过 require 使用,但通过 npm link 命令可以打破这一限制。举个例子,我们已经通过 npm install -g express 安装了 express ,这时在工程的目录下运行命令:
1 | npm link express |
可以在 node_modules 子目录中发现一个指向安装到全局的包的符号链接。通过这种方法,我们就可以把全局包当本地包来使用了。(npm link 命令不支持 Windows。)
包的发布
npm 可以非常方便地发布一个包,比 pip、gem、pear 要简单得多。在发布之前,首先
需要让我们的包符合 npm 的规范,npm 有一套以 CommonJS 为基础包规范,但与 CommonJS
并不完全一致,其主要差别在于必填字段的不同。通过使用 npm init 可以根据交互式问答
产生一个符合标准的 package.json,例如创建一个名为 byvoidmodule 的目录,然后在这个
目录中运行 npm init :
1 | npm init |
这样就在 byvoidmodule 目录中生成一个符合 npm 规范的 package.json 文件。创建一个
index.js 作为包的接口,一个简单的包就制作完成了。在发布前,我们还需要获得一个账号用于今后维护自己的包,使用 npm adduser 根据提示输入用户名、密码、邮箱,等待账号创建完成。完成后可以使用 npm whoami 测验是否已经取得了账号。
接下来,在 package.json 所在目录下运行 npm publish ,稍等片刻就可以完成发布了。打开浏览器,访问 http://search.npmjs.org/ 就可以找到自己刚刚发布的包了。现在我们可以在计算机上使用 npm install byvoidmodule 命令来安装它。
如果你的包将来有更新,只需要在 package.json 文件中修改 version 字段,然后重新使用 npm publish 命令就行了。如果你对已发布的包不满意(比如我们发布的这个毫无意义的包),可以使用 npm unpublish 命令来取消发布。
调试
写程序时免不了遇到 bug,而当 bug 发生以后,除了抓耳挠腮之外,一个常用的技术是单步调试。Node.js 的调试功能正是由 V8 提供的,保持了一贯的高效和方便的特性。
那么如何使用 Node.js 内置的工具和第三方模块来进行单步调试?
命令行调试
1 | // debug.js |
在命令行下执行 node debug debug.js ,将会启动调试工具:
1 | C:\Users\Administrator\Desktop>node debug debug.js |
这样就打开了一个 Node.js 的调试终端,用一些基本的命令进行单步跟踪调试.
| 命 令 | 功 能 |
|---|---|
| run | 执行脚本,在第一行暂停 |
| restart | 重新执行脚本 |
| cont, c | 继续执行,直到遇到下一个断点 |
| next, n | 单步执行 |
| step, s | 单步执行并进入函数 |
| out, o | 从函数中步出 |
| setBreakpoint(), sb() | 在当前行设置断点 |
| setBreakpoint(‘f()’), sb(…) | 在函数f的第一行设置断点 |
| setBreakpoint(‘script.js’, 20), sb(…) | 在 script.js 的第20行设置断点 |
| setBreakpoint(‘script.js’, 20), sb(…) | 显示当前执行到的前后5行代码 |
| clearBreakpoint, cb(…) | 显示当前执行到的前后5行代码 |
| backtrace, bt | 显示当前执行到的前后5行代码 |
| list(5) | 显示当前执行到的前后5行代码 |
| watch(expr) | 把表达式 expr 加入监视列表 |
| unwatch(expr) | 把表达式 expr 从监视列表移除 |
| watchers | 显示监视列表中所有的表达式和值 |
| repl | 在当前上下文打开即时求值环境 |
| kill | 终止当前执行的脚本 |
| scripts | 显示当前已加载的所有脚本 |
| version | 显示 V8 的版本 |
下面是简单的实例
1 | C:\Users\Administrator\Desktop>node debug debug.js |
远程调试
V8 提供的调试功能是基于 TCP 协议的,因此 Node.js 可以轻松地实现远程调试。在命令行下使用以下两个语句之一可以打开调试服务器:
1 | node --debug [= port ] script.js |
node –debug 命令选项可以启动调试服务器,默认情况下调试端口是 5858,也可以使用 –debug=1234 指定调试端口为 1234。使用 –debug 选项运行脚本时,脚本会正常执行,但不会暂停,在执行过程中调试客户端可以连接到调试服务器。如果要求脚本暂停执行等待客户端连接,则应该使用 –debug-brk 选项。这时调试服务器在启动后会立刻暂停执行脚本,等待调试客户端连接。
当调试服务器启动以后,可以用命令行调试工具作为调试客户端连接,例如:
1 | //在一个终端中 |
使用 node-inspector 调试 Node.js
大部分基于 Node.js 的应用都是运行在浏览器中的,例如强大的调试工具 node-inspector。node-inspector 是一个完全基于 Node.js 的开源在线调试工具,提供了强大的调试功能和友好的用户界面,它的使用方法十分简便。
首先,使用 npm install -g node-inspector 命令安装 node-inspector,然后在终端中通过 node –debug-brk=5858 debug.js 命令连接你要除错的脚本的调试服务器,启动 node-inspector:
$ node-inspector
在浏览器中打开 http://127.0.0.1:8080/debug?port=5858 , 即可显示出优雅的 Web 调试工
具.node-inspector 的使用方法十分简单,和浏览器脚本调试工具一样,支持单步、断点、调用栈帧查看等功能。(node-inspector 使用了 WebKit Web Inspector,因此只能在 Chrome、Safari等 WebKit 内核的浏览器中使用,而不支持 Firefox 或 Internet Explorer。)