读 《node.js实战2.0》,进行学习记录总结。
Node编程基础
本章内容:
- 用模块组织代码
- 用回调处理一次性时间
- 用事件发射器处理重复性事件
- 实现串行和并行的流程控制
- 使用流程控制工具
本章要解决摆在Node 新手开发面前的两个难题:
- 如何组织代码
- 如何实现异步编程
- 如何响应一次性事件
- 如何处理重复性事件
- 如何让异步逻辑顺序执行
Node 功能的组织及重用
传统的方式是按逻辑相关性对代码分组,将包含大量代码的单个文件分解成多个文件。
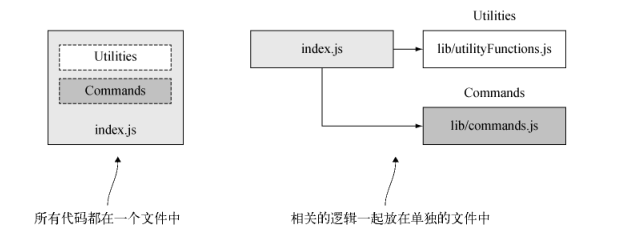
对于整合一个文件(’included’文件)中的逻辑,后面引入这个文件里面的任何变量或者是函数可能会覆盖应用程序原来的相同的变量或者是函数。
在PHP中可以使用 命名空间 解决这个问题, Ruby 通过模块也提供了类似的功能。但 Node 的做法是不给你有污染命名空间的机会。
Node 模块打包代码是为了重用,但是不会改变全局作用域。Node 模块允许从被引入文件中选择要暴露给程序的函数和变量,如果模块返回的函数或者变量不止一个,那么它可以通过设定 exports 对象的属性来指明它们。如果这个模块只返回一个函数或者变量,则可以设定 module 属性。
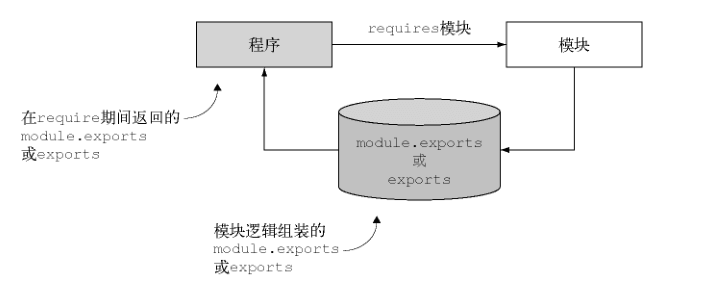
Node 模块系统避免了对全局作用域的污染,从而也就避免了命名冲突,并简化了代码的重用。模块还可以发布到 npm 存储库中。使用线上这些模块没有必要担心会覆盖其他模块的变量和函数。
下面将会通过一个实例来说明把逻辑组织到模块中,需要注意的几个问题:
- 如何创建模块
- 模块放在文件系统中的什么地方
- 在创建和使用模块时要注意的东西
开始一个新的 Node 项目
创建一个文件,在该目录下输入
1 | npm init -y |
-y 代表 yes,这样 npm 就会创建一个全部使用默认值的 package.json 文件。如果想要更多的控制权,则去掉 -y,就可以自定义 授权许可、作者名字等等…不过这些都没有什么必要吧,因为你也可以手动再去修改初始化的 package.json 文件。
创建模块
模块既可以是一个文件,也可以是包含一个或者多个文件的目录。如果模块是一个目录,Node通常会在这个目录下找一个叫 index.js的文件作为模块的入口。典型的模块是一个包含 exports 对象属性定义的文件,这些属性可以是任意类型的数据,比如字符串、对象和函数。
创建一个模块,来进行货币转换。
1 | const canadianDollar = 0.91; |
exports 对象上只设定了两个属性。也就是说引入这个模块的代码只能访问到 canadianToUS 与 USToCanadian两个函数。而变量 canadianDollar 作为私有变量仅作用在 这两个函数的逻辑内部,程序并不能直接访问它。
使用这个模块要用到 Node 的 require 函数,该函数以所用模块的路径为参数。Node 以同步的方式寻找模块,定义到这个模块并加载文件中的内容。Node 查找文件的 顺序是先找到核心模块,然后是当前目录,最后是 node_modules
关于 require 和 同步I/O
require 是 Node 中少数几个同步 I/O操作之一。因为经常用到模块,并且一般都是在文件顶端引入,所以把 require 做成同步的有助于代码的整洁、有序。
但在I/O密集的地方尽量不要用 require。所有同步调用都会阻塞 Node,知道调用完成才能做其他事情。比如你正在运行一个 HTTP 服务器,如果在每个进入的请求上都用了 require,就会遇到性能问题。所以 require 和其他同步操作通常放在最初加载的地方。
下面这个是 test-currency.js 中的代码,它 require 了 currency.js 模块
1 | // 路径 ./ 代表模块跟程序脚本放在同一个目录下 |
引入时,.js 扩展名可以忽略。如果没有指明是 js文件,Node也会检查 json 文件,json 文件就是作为 JavaScript 对象加载的。
在 Node 定位到并计算好你的模块之后, require 函数会返回这个模块中定义的 exports 对象中的内容,然后你就可以用这个模块中的两个函数做货币转换了。
如果想把这个模块放在子目录,比如 ’/lib‘,只要把 require 语句改成下面的就可以了
1 | const currency = require('./lib/currency'); |
组装模块中的 exports 对象是在单独的文件中组织可重用代码的一种简便方法。
用 module.exports 微调模块的创建
尽管用函数和变量组装 exports 对象能满足大多数的模块的需要,但有时你可能需要调用不同的模型来创建该模块。
比如说,前面创建的那个货币转换器模块可以改成只返回一个 Currency 构造函数,而不是一个包含两个函数的对象。一个面向对象的实现看起来可能想下面这样:
1 | const Currency = require('./currency'); |
如果只需要从模块中得到一个函数,那从 require 中返回一个函数的代码要比返回一个对象的代码更加优雅。
要创建一个变量或者函数的模块,你可能会以为只要把 exports 设定你想返回的东西就行。但是这样是不行的,因为 Node 觉得不用任何其他对象、函数或者变量给 exports 赋值。下面代码清单中的模块代码视图将一个函数赋值给 exports
1 | // 这个模块不能用 |
为了让前面那个模块可用,需要把 exports 换成 module.exports 。用 module.exports 可以对外提供单个变量、函数或者对象。如果你创建了一个既有 exports 又有 module.exports 的模块。那么它会返回 module.exports ,而 exports 会被忽略。
导出的究竟是什么
最终在程序里导出的是 module.exports。 exports 只是对 module.exports 的全局引用,最初被定义为一个可以添加属性的空对象。 exports.myFunc 只是 module.exports.myFunc 的简写。
所以,如果把 exports 设定为别的,就打破了 module.exports 之间的引用关系。可是因为真正导出的是 module.exports,那样 exports 就不能用了,因为它不再指向 module.exports 了。如果你想保留那个链接,可以像下面这样让 module.exports 再次引用 exports:
1 | module.exports = exports = Currency; |
根据需要使用 exports 或 module.exports 可以将功能组织成模块,规避将程序脚本一直增长所产生的弊端。
用 node_module 重用模块
要求模块在文件系统中使用相对路径存放,对于组织程序特定的代码很有帮助,但对于想要在程序房间共享或跟其他人共享代码却用处不大。Node 中有一个独特的引用机制,可以不必知道模块在文件系统中的具体位置。这个机制就是使用 node_modules 目录。
如果引入的时候省略掉路径,直接写文件名,Node 会遵照几个柜子搜寻这个模块
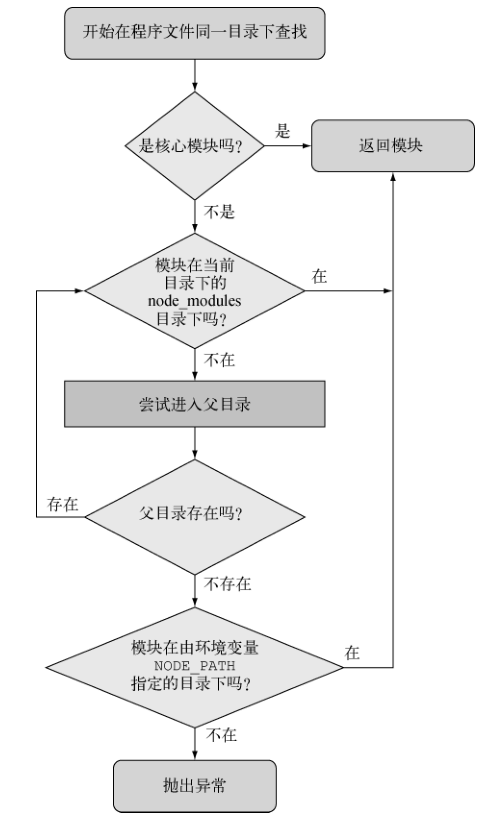
用环境变量 NODE_PATH 可以改变 Node 模块的默认路径。如果用了它,在 Window 中 NODE_PATH 应该设置为用分号分隔的目录列表,在其他操作系统中则用冒号分隔。
注意事项
尽管Node模块系统的本质简单直接,但是有两点需要注意一下。
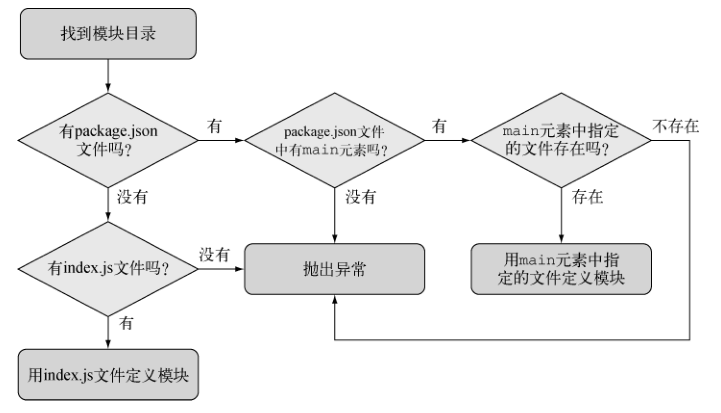
第一,如果模块是目录,在模块目录中定义模块的文件必须被命名为 index.js ,除非你在这个目录下一个叫 package.json 的文件里特别指明。要指定一个取代 index.js 的文件,package.json 文件里必须有一个用 JavaScript 对象表示法 (JSON)数据定义的对象,其中有一个名为 main 的键,指明模块目录内文件的路径。下面的流程图对这些规则做了汇总。
下面是一个 package.json 文件的例子,它指定 currency.js 为主文件
1 | { |
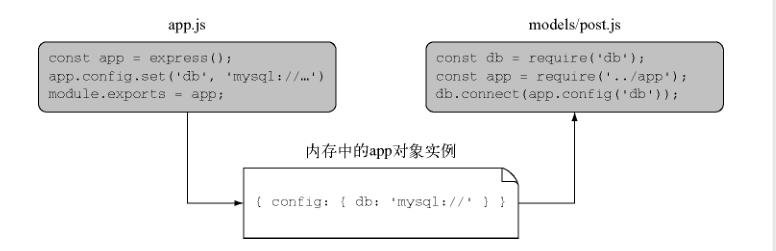
第二,Node 能把模块作为对象缓存起来,如果程序中的两个文件引入了相同的模块,第一个 require 会把模块返回的数据存到内容中,这样第二个 require 加不用再去访问和计算模块的源文件了。也就是说,同个进程中使用 require 加载一个模块得到的是相同的对象。假设你搭建了一个 MVC Web 程序,它有一个主对象 app。你可以设置好那个 app 对象,导出它,然后在项目中的任何地方 require 它。如果你在这个 app 对象中放了一些配置信息,那你就可以在其他文件访问这些配置信息的值,假设目录接口如下:
1 | project |
下面展示它的工作原理
使用异步编程技术
服务端异步编程:事件也会触发响应逻辑,在Node 的世界流行两种响应逻辑管理方式,回调和事件监听。
回调通常用来定义一次性响应的逻辑,比如对于数据库查询,可以指定一个回调函数来确定如何处理查询结果。这个回调函数可能会显示数据库查询结果,根据这些结果来做些计算,或者以查询结果为参数执行另一个回调函数。
事件监听器本质上也是一个回调,不同的是,它是一个概念实体(事件)相关联。例如,当有人在浏览器点击鼠标时,鼠标点击就是一个需要处理的事件。在node 中,当有 HTTP 请求过来时候,HTTP服务器会发出一个 request 事件。你可以监听那个 request 事件,并添加一些响应逻辑。在下面的例子中,用 EventEmitter.prototype.on 方法在服务器上绑定了一个监听器,所以每当有 request 事件发出时,服务器就会调用 hanldeRequest 函数:
1 | server.on('request',handleRequest); |
一个 Node HTTP 服务器实例就是一个事件发射器,一个可以继承、能够添加事件发射及处理能力的类(EventEmitter)。Node 的许多核心功能都继承自 EventEmitter ,你也能创建自己的事件发射器。
Node 有两种常用的响应逻辑组织方式,我们刚才用了一种,接下来要了解它的工作机制:
- 如何用回调处理一次性事件
- 如何用事件监听器响应重复性事件
- 异步编程的几个难点
用回调处理一次性事件
回调是一个函数,它被当做参数传给异步函数,用来描述异步操作完成之后要做什么。回调函数 在 Node 开发使用得很频繁,比事件发射器用得多,并且用起来也很简单。
为了演示回调的用法,我们来做一个简单的 HTTP 服务器,让它实现以下的功能
- 异步获取存在 JSON 文件中的文章的标题
- 异步获取简单的HTML 模块
- 把那些标题组装到 HTML 页面中
- 把 HTML 页面发送给用户
JSON 文件(title.json)会被格式化陈给一个包含文章标题的字符串数组,内容如下:
1 | [ |
HTML 文件 template.html 如下结构,可以插入博客文章的标题
1 |
|
获取 JSON 文件中的标题并渲染 Web 页面的代码如下:
1 | // blog_recent.js |
这这个例子中,嵌套了三层
1 | http.createServer((req, res) => { ... |
三层还可以,但是调用层数越多,代码看起来越乱,重构和测试起来也很困难,所以最好限制一下回调的嵌套层级。如果把每一层回调嵌套的处理做成命名函数,虽然表示相同逻辑所用的代码变多了,但维护、测试和重构起来会跟更容易。下面代码创建了中间函数来减少嵌套
1 | const http = require('http'); |
还可以用 Node 开发中的另一种惯用法来减少由 if/else 引起的嵌套,尽早从函数中返回。
通过尽快返回减少嵌套的例子:
1 | const http = require('http'); |
我们已经知道如何使用一次性任务定义响应了。上面的读取文件和响应 Web 服务器请求。
Node 的异步回调惯例
Node 中的大多数内置模块在使用回调时都会带两个参数,第一个用来放可能会发生的错误,第二个用来放结果。错误参数经常缩写为 err。
用事件发射器处理重复性事件
事件处理器会触发事件,并且在那些事件被触发时能处理它们,一些重要的Node Api 组件,比如 HTTP 服务器、TCP 服务器和流,都被做成了事件发射器。我们也可以创建自己的事件发射器。
事件是通过监听器进行处理的。监听器是跟事件相关联的、当有事件出现时就会触发的回调函数。比如 Node 中的 TCP socket ,它有一个 data 事件,每当 socket 中有新数据时就会触发:
1 | socket.on('data', handleData); |
事件发射器示例
echo 服务器就是一个处理重复性事件的简单例子,当你给它发送数据时,它会把数据发回来。
实现一个 echo 服务器,当有客户端连接上来时,它就会创建一个 socket 。socket 是一个事件发射器,可以用 on 方法添加监听器响应 data 事件。只要 socket 上有新数据过来,就会发这些 data 事件。
1 | const net = require('net'); |
用下面的命令运行 echo 服务器:
1 | node echo_server.js |
echo 服务器运行起来之后,就可以用下面的命令连上去(可以另开一个终端):
1 | telnet 127.0.0.1 8888 |
每次通过 telnet 会话把数据发送给服务器,数据都会回传到 telnet会话中,意味着你每打一个字母,它也会返回对应的字母。
window 的 telnet 是默认不开启的。具体怎么开启可以看这里。
响应只应该发生一次的事件
监听器可以被定义成持续不断被地响应事件,如前面的例子,也能被定义成只响应一次,下面的代码用了 once 方法,对前面的那个 echo 服务器做了修改,让它只回应第一次发送过来的数据。
1 | const net = require('net'); |
创建事件发射器:一个 PUB/SUB 的例子
前面的例子用了一个带事件发射器的 Node 内置 API。然后我们可以用 Node 内置的事件模块创建自己的事件发射器。
下面代码定义了一个 channel 事件发射器,带有一个监听器,可以向加入频道的人做出相应。注意这里用 on (或者用较长的 addListener)方法给事件发射器添加了监听器:
1 | const EventEmitter = require('events').EventEmitter; |
事件名称:事件是可以具有任意字符串值的键:data、join或某些长的让人发疯的事件名都行。只有一个事件是特殊的,那就是 error 。
接着用 EventEmitter 实现自己的发布/预定逻辑,做一个通信通道。如果运行了下面的代码,就会得到一个简单的聊天服务器。聊天服务器的频道被做成了事件发射器,能对客户端发出的 join 事件做成响应。当有客户端加入聊天频道时,join 监听器逻辑会将一个针对该客户端的监听器附加到频道上,用来处理会将所有广播消息写入改客户端 socket 的 broadcast 事件。事件类型的名称,比如 join 和 broadcast ,完全是随意取的。你可以按自己的喜好给它们换个名字。
用事件发射器实现简单的发布/预定系统
1 | const events = require('events'); |
把聊天服务器跑起来后,打开两个新的命令行窗口,并在两个都输入下面的命令进入聊天程序:
1 | telnet 127.0.0.1 8888 |
在其中任何一个窗口输入的内容都会被发送到其他所有窗口中。
这个聊天服务器还有一个问题,在用户关闭连接离开聊天室后,原来的那个监听器还在,仍会尝试向已经断开连接写数据。这样自然就会出错。为了解决这样的问题,还要按照下面的代码清单把监听器加到频道事件发射器上,并且向服务器的 close 事件监听器中添加发射频道的 leave 事件的处理逻辑。leave 事件本质上就是要移除原来给客户端添加的 broadcast 监听器。
创建一个在用户断开连接时能 “打扫战场”的监听器
1 | const events = require('events'); |
如果你想停止提供聊天服务,但是又不想关掉服务器的,可以用 removeAll-Listeners 事件发射器方法去掉给定类型的全部监听器。
1 | channel.on('shutdown',() =>{ |
然后你可以添加一个停止服务的聊天命令。为此需要将 data 事件的监听器改成下面这样:
1 | client.on('data',data =>{ |
现在只要有人输入 shutdown 命令,所有参与聊天的人都会被踢出去。
错误处理
在错误处理上有一个常规做法,你可以创建发出 error 类型事件的事件发射器,而不是直接抛出错误,这样就可以为这事件类型设置一个或者多个监听器,从而定制的事件响应逻辑。
下面的代码显示的是一个错误监听器如何将发出的错误输出到控制台中:
1 | const events = require('events'); |
如果发出这个 error 事件流类型没有该事件类型的监听器,事件监听器会输出一个栈跟踪(到错误发生时所执行的程序指令列表)并停止执行。栈跟踪会用 emit 调用的第二个参数指明错误类型。这是只有错误类型事件才能享受的特殊待遇,在发出没有监听器的其他事件类型时,什么也不会发生。
如果发出的 error 类型事件没有作为第二个参数的 error 对象,栈跟踪会指出一个 ”为捕获、未指明的‘错误’事件“错误,并且程序会停止执行。可以用一个已经废除的方法来处理这个错误,用下面的代码顶一个全局的处理器实现响应逻辑
1 | process.on('uncaughtException',err =>{ |
让连接上面的用户看到当前有几个已链接的聊天对象,可以用下面这个监听器方法,它能根据给定的事件类型返回一个监听器数组:
1 | channel.on('join', function (id, client) { |
为了增加能够附加到事件发射器上的监听器数量,不让Node 在监听器数量超过 10个时发出警告,可以用 setMaxListeners 方法。以该频道事件发射器为例,可以用下面的代码增加监听器的数量:
1 | channel.setMaxListeners(50); |
扩展事件监听器:文件监听器
如果你想在事件发射器的基础上构造程序,可以创建一个新的 javaScript 类继承事件发射器。
比如创建一个 watcher 类来处理放在某个目录下的文件,然后可以用这个类创建一个工具,该工具可以监视目录(将放在里面的文件名都改为小写,并将文件复制到一个单独目录中)
设置好 Watcher 对象后,还需要加两个新方法来扩展继承自 EventEmitter 的方法,代码如下:
1 | const fs = require('fs'); |
watch 方法循环目录,处理其中的所有文件。start 方法启动对目录的监控。监控用到了 Node 的 fs.watchFile 函数,所以当被监控的目录中有事情发生的时候,watch方法就会触发,循环遍历整个受监控的目录,可以用一下代码创建一个 Watcher 对象:
1 | const watcher = new Watcher(watchDir,processedDir); |
注意,watchDir为观察的文件名, processedDir为文件进程处理后要放置的文件名
有了新创建的 Watcher 对象,就可以继承自事件发射器类的 on 方法设定每个文件的处理逻辑,如下所示:
1 | watcher.on('process',(file) =>{ |
接着就可以启动对目录的监控:
1 | watcher.start(); |
新建 watch 和 done 目录,然后输入目标文件名和完成之后的文件名:
1 | const watchDir = 'watch'; |
运行你所命名的文件名:
1 | node Extended_Emitter.js |
接着把文件丢到 watch 目录中,然后看着文件出现在 done 目录中,文件名被改成小写。这就是用事件发射器创建新类的例子。
学习了使用回调定义一次性异步逻辑,已经如何用事件发射器重复派发异步逻辑。我们可能还想在单个回调或事件发射器的监听器中添加新的异步任务。如果这些任务的执行顺序很重要,就会面对新的难题:如何准确控制一系列异步任务里的每个任务。
异步开发的难题
在创建异步程序的时候,必须密切关注程序的执行流程,盯着程序的状态:事件轮询的条件、程序变量,以及其他随着程序逻辑执行而发生变化的资源。
比如说,Node 的事件轮询会跟踪还没有完成的异步逻辑。只要有异步逻辑未完成,Node 进程就不会退出。一个持续运行的 Node 进程对 Web 服务器之类的应用来说很有必要,但对于命令行工具这种经过一段时间后就应该结束的应用却意义不大。事件轮询会跟踪所有数据库连接,直到它们关闭,以防止 Node 退出。
下面是一段可能因为执行顺序而导致混乱的异步代码,如果例子中的代码能够同步执行,那么应该输出的是 ‘The color is blue’,可这个例子是异步的,在 console.log 执行之前的 color 的值还在变化,所以输出的是 ‘The color is green’.
1 | // 作用域如何到导致 bug 出现的 |
用 JavaScript 闭包可以 ‘冻结’color 里面的值,在下面的代码中,对 asyncFunction 的调用被封装到了一个 以 color 为参数的匿名函数里。这样就可以马上执行这个匿名函数,把当前的 color 的值传给它。而 color 变成了匿名函数的采纳数,也就是这个匿名函数内部的本地变量,当匿名函数外面的 color 值发生变化的时候,本地的 color 不会受到影响
1 | // 用匿名函数保留全局变量的值 |
闭包是 Node 开发中要经常用到的一个编程技巧,接着看看怎么让异步逻辑顺序执行,好掌握程序的流程。
异步逻辑的顺序化
在异步程序的执行过程汇中,有些任务可能会随时发生,跟程序中的其他部分在做什么没有关系,什么时候做这些任务都不会出问题。但有些任务只能在某些特定的任务之前或之后做。
让一组异步任务顺序执行的概念也被 Node 社区称为流程控制。这种控制分成两类:串行和并行:

需要一个接着一个执行的任务叫作串行任务。创建一个目录并往里放一个文件的任务就是串行的。你不能在创建目录前往里放文件。
不需要一个接着一个执行的任务叫作并行任务。这些任务彼此之间开始和结束的时间并不重要,但在后续逻辑执行之前它们应该全部执行完。下载几个文件然后把它们压缩到一个 zip归档文件中就是并行任务。这些文件的下载可以同时进行,但在创建归档文件之前应该全部下载完。
跟踪串行和并行的流程控制要做编程记账的工作。在实现串行化流程控制时,需要跟踪当前
执行的任务,或维护一个尚未执行任务的队列。实现并行化流程控制时需要跟踪有多少个任务要执行完成了。
有一些可以帮助记账的流程控制工具,它们能够让组织异步的串行或并行化任务变得很容易。尽管社团创建了许多序列化异步逻辑的辅助工具。但亲自动手是实现流程控制可以让我们看透其中的玄机。
何时使用串行流程控制
可以使用回调让几个异步任务按顺序执行,但是如果任务很多,就必须组织一下,否则过多的回调嵌套会把代码搞得很乱。
下面的这段代码就是用回调让任务顺序执行的。这里例子用 setTimeout 模拟需要花时间执行的任务:第一个任务用了1秒,第二个0.5秒,最后一个十分之一秒。setTimeout 只是一个人工模拟,在真正的代码中可能是读取文件、发起HTTP 请求。
1 | setTimeout(() =>{ |
此外,也可以用 Async 这样的流程控制工具执行这些任务。Async 用起来简单直接,并且代码量小。安装Async
1 | npm i async |
简化代码:
1 | const async = require('async'); |
尽管这种用流程控制实现的代码很多,但通常可读性和可维护性更强,一般也不会一直用流程控制,当碰到想要躲开回调嵌套的情况是,它就会是改善代码可读性的好工具了。
看过这个用特制工具实现串行化流程控制的例子后,我们看看怎么从头实现它。
实现串行化流程控制
为了用串行化流程控制让几个异步任务按顺序执行,需要先把这些任务按预期的执行顺序
放到一个数组中。这个数组将起到队列的作用:完成一个任务后按顺序从数组中取出下一个。
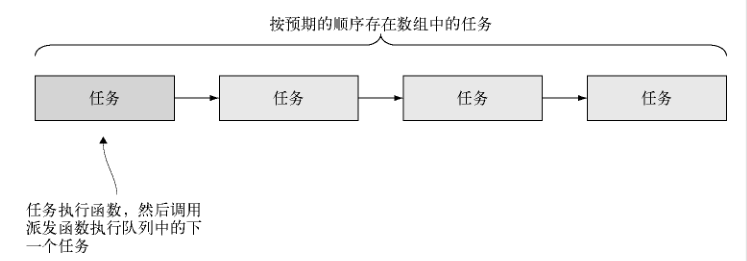
数组中的每个任务都是一个函数,任务完成之后应该调用一个处理函数,告诉它错误状态和结果。在这一实现中,如果有错误,处理器函数就会终止,否则就从队列中取出下一个任务执行它。
实现一个小程序,让它从一个随机选择的 RSS 预订源中获取一篇文章的标题和URL,并显示出来,RSS预订源列表放在一个文本文件中。这个程序的输出是像下面这样的文本:
1 | Of Course ML Has Monads! |
需要从 npm 下载两个辅助模块。
1 | npm i --save request@2.60.0 |
request 模块是个经过简化的 HTTP 客户端,你可以用它获取 RSS 数据。 htmlparser 模
块能把原始的 RSS数据转换成 JavaScript数据结构。
创建一个 index.js 文件
1 | const fs = require('fs'); |
在试用这个程序之前,先在程序脚本所在的目录下创建一个 rss_feeds.txt 文件。如果你自己没有预订源,可以试一下 Node 博客,地址是 http://blog.nodejs.org/feed/。把预订源 URL 放到这个文本文件中,每行一条。文件创建好后,打开命令行窗口输入下面的命令进入程序所在目录并执行脚本:
1 | node index.js |
接着在控制台可以看到这样的结果:

如本例中的实现所示,串行化流程控制本质上是在需要时让回调进场,而不是简单地把它们
嵌套起来。
现在已经知道怎么串行化流程控制了,接下来看看如何让异步任务并行执行。
实现并行化流程控制
为了让异步任务并行执行,仍然是要把任务放到数组中,但任务的存放顺序无关紧要。每个任务都应该调用处理器函数增加已完成任务的计数值,当所有任务都完全后,处理器函数应该执行后续的逻辑。
下面实现一个简单的程序作为并行化流程控制的例子,它会读取几个文本文件的内容,并输出单词在整个文件中出现的次数。我们会用异步的 readFile 函数读取文本文件的内容,所有几个文件的读取可以并行执行。
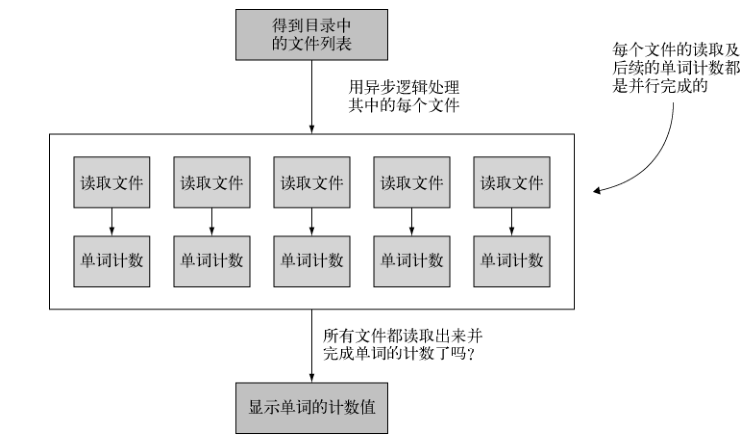
这个程序的输出看起来应该像是下面这样(尽管实际上可能要长很多)
1 | would:2 |
新建一个要分析的文本文件的文件夹:text.
实现并行化流程控制的代码:
1 | // word_count/word_count.js |
执行:
1 | node word_count.js |
可以看到大概这样的结果:
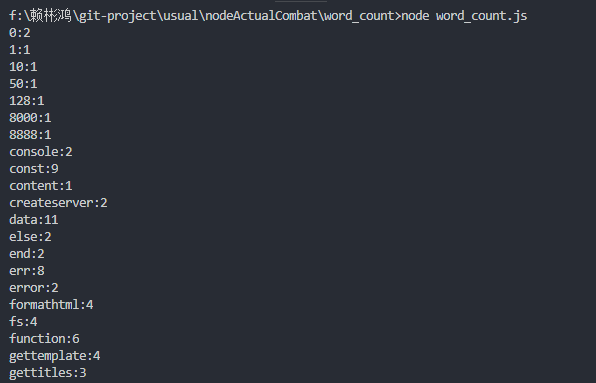
现在,我们已经知道串行和并行的流程化控制的底层机制了,接下来可以用社区贡献的工具在程序中实现流程控制,而不必自己实现。
利用社区里的工具
社区中的很多附加模块都提供了方便好用的流程控制工具,比较流行的是 Async、Step 和 Seq 三个。
总结
- Node 模块可以被组织可重用的模块
- require 函数是用来加载模块的
- module.exports 和 exports 对象是用来分享模块内的函数和变量的
- package.json 文件是用来指明依赖项的,还要指明将哪个文件作为主文件
- 异步逻辑可以用来嵌套回调、事件发射器和流程控制工具来控制。